
Lambda(Golang)でBedrockのバッチ推論(Amazon Nova Micro)を動かしたときの手順を備忘録として残しておく。
バッチ推論に必要なIAMとS3とLambdaはterraformで作成する。
参考にする方へ、terraform周りの知識があんまりないので、記述とかおかしいかもしれないですが、あんまり気にしないで見てください。
環境
- Golang1.22
- AWSSDKv2
- Lambda(AL2)
- AWS Nova Micro
- terraform
- Docker
プロジェクト
Nova Microを有効化
バージニアリージョン(us-east-1)でAWS Nova Microのモデルを有効化する。
マネージコンソールからAmazon Bedrock→Configure and learnのモデルアクセス→モデルアクセスを変更→Nova Microを選択する→次へ→送信。
「アクセスが付与されました」となっていればOK
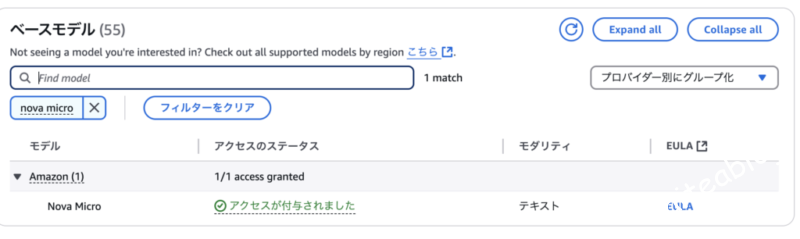
※注意:リージョンごとに有効かの情報は別れてる。
※注意:モデルを有効化するために、ポリシー許可が必要。
必要なポリシーは下記サイトの25ページ参照。
バッチ推論のInputとOutputを格納するS3バケット作成
バッチ推論でインプットとアウトプットを格納するバケットをバージニアリージョン(us-east-1)に作成。
今回は「trial-bedrock-batch-start」というバケットで作成
バッチ推論を動かすためのロールとポリシー作成
バッチ推論ジョブをうごかすためのIAMを作成する。
今回は「trial-bedrock-execution-role」というロール名で作成
model-invocation-jobのarnと作成したバケットに対しての以下のポリシーがあれば問題ないぽい。
- GetObject
- PutObject
- ListBuket
IAM作成後、IAMのarnを控えておくと後々手間が省ける。
ロール、ポリシーは下記リンクを参考に作成。

{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "[アカウントID]"
},
"ArnEquals": {
"aws:SourceArn": "arn:aws:bedrock:us-east-1:[アカウントID
ID]:model-invocation-job/*"
}
}
}
]
}{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": [
"[アカウントID]"
]
}
},
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::trial-bedrock-batch-start",
"arn:aws:s3:::trial-bedrock-batch-start/*"
],
"Sid": "S3Access"
}
]
}バッチ推論を動かすLambdaのロール作成
Lambdaを動かす際のロールに下記を指定してあげる必要がある。
- AWSLambdaBasicExecutionRole
- bedrock:CreateModelInvocationJob
- iam:PassRole
今回は「trial-lambda-bedrock-execution-role」というロール名で作成。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"bedrock:CreateModelInvocationJob"
],
"Effect": "Allow",
"Resource": "*",
"Sid": "BedrockModelInvocation"
},
{
"Action": [
"iam:PassRole"
],
"Effect": "Allow",
"Resource": [
"[trial-bedrock-execution-roleのarn]"
],
"Sid": "PassRole"
}
]
}PassRoleを設定しないと、Lambdaからtrial-bedrock-execution-roleを動かすことができないので、注意。
PassRoleの説明については下記のサイトがシンプルでわかりやすかった。

Lambdaの作成
バージニアリージョン(us-east-1)でruntime:AL2のLambdaを作成する。
実行ロールは「trial-lambda-bedrock-execution-role」を選択する。
データの準備
バッチ推論を使う場合、データは最低1000レコードないといけないらしいので、レコードが1000件あるデータを拡張子jsonlで作成する。
サイトによっては最低100件からでも動いたとかあるので、1000件は必要ないかもしれないが、BlackBeltの資料に最低1000件って書いてあるので、合わせる。
追記:100件ぐらいでも動いた。
AWS Nova Microの場合、データフォーマットは以下の感じ。
※AIモデルによって、フォーマットが変わるので注意。
{"modelInput": {"messages": [{"role": "user", "content": [{"text": [指示内容]}]}]}}
例
{"modelInput": {"messages": [{"role": "user", "content": [{"text": "あなたは野菜についてとても詳しい博士です。与えた品名の情報を20字程度で簡潔に説明してください。品名:りんご"}]}]}}データ自体は適当にChatGPTに作成してもらった。
データ作成後、trial-bedrock-batch-startバケットにアップロード。
ソースの準備
バッチ推論を動かすためのプログラムを作成する。
大事な部分だけ記載する。
他はGithubのプロジェクト参照すればわかると思う。
// job名は同じ名前で作成することができないので、timestampなどつけて動的な名前にしてあげる
jobName := fmt.Sprintf("bedrock-test-job1-%s", timestamp)
// 使用したいmodelIDを指定する。AWS Nova Microを利用する際は下記のように指定。
// 他のmodelIDは公式ドキュメント参照。https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/models-supported.html
modelId := "amazon.nova-micro-v1:0"
// trial-bedrock-execution-roleのロールarnを指定。
// AWSAccountIDは公開しない方がいいらしいので環境変数に設定しているが、参考にする人は普通にarnを指定すればOKです。
roleArn := fmt.Sprintf("arn:aws:iam::%s:role/trial-bedrock-execution-role", awsAccountId)
// バッチ推論に使う、ファイルのS3URIを指定。
inputS3Uri := "s3://trial-bedrock-batch-start/trial_bedrock_input.jsonl"
// バッチ推論の結果を出力するS3URIを指定。
outputS3Uri := "s3://trial-bedrock-batch-start/"
実行&確認
Lambdaにデプロイして、マネコンのテストから動かす。
Lambdaが正常に実行されたら下記手順で、バッチ推論のジョブが動いているかの確認。
AmazonBedrock→Infer→Batch inference
Statusの部分が「InProgress」になってればとりあえずジョブの実行は成功。

InProgressにならずにFailedになっている場合はそもそもデータが取れなかったり、必要な件数分なかったりする恐れがある。
各ステータスについては下記AWSサイトのstatus項目を参照。

ジョブがInProgressになったら、アウトプットが作られ始めるので、確認し、正常に動作していることを確認する。
※Job実行中でも、アウトプットを確認しても問題ない。
modelOutputが正常に入っていれば問題なし。
{"modelInput":{"messages":[{"role":"user","content":[{"text":"あなたは野菜についてとても詳しい博士です。与えた品名の情報を20字程度で簡潔に説明してください。品名:かぼちゃ"}]}]},"modelOutput":{"output":{"message":{"content":[{"text":"かぼちゃは秋の代表野菜で、栄養豊富で煮物やスイーツに使われる。"}],"role":"assistant"}},"stopReason":"end_turn","usage":{"inputTokens":37,"outputTokens":26,"totalTokens":63,"cacheReadInputTokenCount":0,"cacheWriteInputTokenCount":0}},"recordId":"75"}
{"modelInput":{"messages":[{"role":"user","content":[{"text":"あなたは野菜についてとても詳しい博士です。与えた品名の情報を20字程度で簡潔に説明してください。品名:だいこん"}]}]},"modelOutput":{"output":{"message":{"content":[{"text":"だいこんは白い根菜で、辛味が強く、煮物や漬物に使われる。"}],"role":"assistant"}},"stopReason":"end_turn","usage":{"inputTokens":37,"outputTokens":28,"totalTokens":65,"cacheReadInputTokenCount":0,"cacheWriteInputTokenCount":0}},"recordId":"14"}
{"modelInput":{"messages":[{"role":"user","content":[{"text":"あなたは野菜についてとても詳しい博士です。与えた品名の情報を20字程度で簡潔に説明してください。品名:アスパラガス"}]}]},"modelOutput":{"output":{"message":{"content":[{"text":"アスパラガスは春の野菜で、緑色の茎が栄養価高く人気。"}],"role":"assistant"}},"stopReason":"end_turn","usage":{"inputTokens":38,"outputTokens":25,"totalTokens":63,"cacheReadInputTokenCount":0,"cacheWriteInputTokenCount":0}},"recordId":"30"}Bedrockのバッチ推論の記事少なすぎ!!
まじで苦労した。
AIに大量にデータ処理させたいと思ったらBedrockを見つけたが、いざ、やってみたら情報が少なくて、モデルによってファイルのフォーマット違ったり、BlackBeltに書かれている内容じゃできなかったりで超大変だった。
ただ、今後使う機会とか増えてきそうだし、同じ問題にぶち当たった人向けに備忘録として残しておく。
Terraformの勉強にもなったし、あんまり記事にされて内容を記事にできたからよかった。
今回から見出し使って書いてみたけどこっちの方が見やすそう??
参考サイト達
https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2024_Amazon-Bedrock-Model-Inference-b_0909_v1.pdf


